
Главная » CADmaster №2(101) 2023 » Архитектура и строительство Через тернии к... автоматической экспертизе цифровой информационной модели
Давным-давно...
Все началось в далеком уже 2016 году, когда Президент России поручил в срок до 1 декабря разработать и утвердить план мероприятий по внедрению технологий информационного моделирования в сфере строительства (BIM).
С тех пор утекло много воды, о BIM-проектировании стали говорить даже те, кто к строительству имел весьма опосредованное отношение. Умы и мысли регулярно будоражились новыми поручениями и новыми сроками. Затем стали появляться новости одна другой фантастичнее: о полном внедрении BIM, о первых прохождениях экспертизы с BIM-моделью, о переходе к BIM на отечественном ПО… Сотни публикаций, отчетов, споры до хрипоты о терминологии, которые привели к тому, что звучное BIM (англ. Building Information Model) было заменено не менее звучным ТИМ (Технология информационного моделирования). Теоретически страна в едином порыве готовилась покорять космические пространства, и это не могло не пугать вдохновлять разработчиков ПО.
Но что же на практике? А на практике оказалось, что даже спустя годы внедрений и после километров публикаций об успехе подавляющее большинство проектных компаний испытывает сомнения в практической целесообразности применения технологии информационного моделирования. И в этом нет ничего странного, если учесть, что создание цифровой информационной модели (ЦИМ) требует:
- дополнительных трудозатрат;
- специальных профессиональных навыков у сотрудников;
- особенной организации взаимодействия специалистов.
И все ради чего? Ради красивой трехмерной картинки, которую можно так эффектно покрутить перед заказчиком?
О пользе применения технологии информационного моделирования много говорили на самых высоких уровнях. Это и удобное управление графиком строительства, и организация процесса строительного надзора, и учет расхода средств и материалов, и, наконец, наглядность контроля на этапе эксплуатации. Но ведь пока сам не пощупаешь, невозможно в полной мере осознать всю пользу?
Вот и вышло, что на этапе проектирования весь смысл цифровой информационной модели сводился к поиску геометрических пересечений между моделями разных дисциплин. И это, конечно, было полезно. Но душа требовала большего, особенно если учесть, что мы живем в эпоху победивших информационных технологий. Поэтому вскоре все заговорили об автоматическом поиске нормативных нарушений, а затем и об автоматическом проектировании в соответствии со стандартами.
Это присказка, а сказка…
Грандиозные планы разбивались о многолетние наслоения норм и стандартов, применявшихся в проектировании. Часть из них действовала еще с советских времен и, конечно же, устарела, часть только вступила в силу, но уже противоречила существующим требованиям, а порой и здравому смыслу. Одно было очевидно — с такой базой чуда не произойдет.
Решение было подсказано нашими западными тогда еще партнерами, и называлось это решение SMART 1-стандартами.
Согласно схеме развития стандартизации по классификации ИСО/МЭК (рис. 1), нормативные документы должны пройти несколько стадий эволюции.
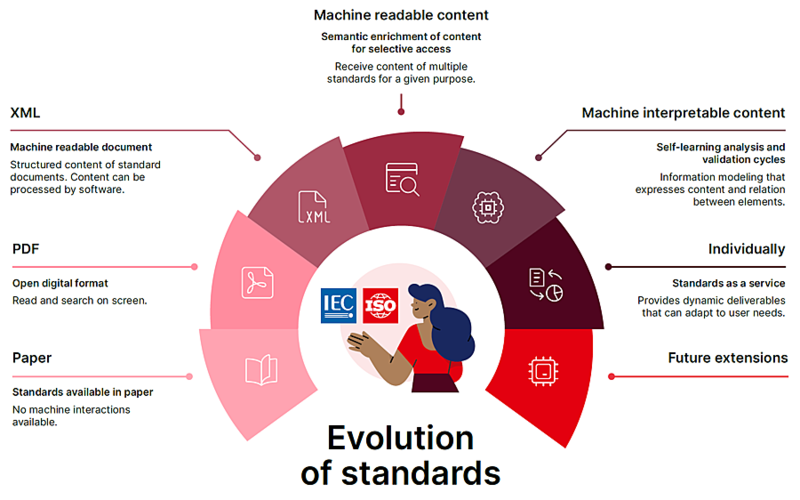
Если совсем в двух словах, то бумажные стандарты развиваются в электронные версии — PDF, далее текст распознаётся и в структуре выделяются требования. Тут уже документ становится машиночитаемым, а когда множество машиночитаемых документов складывают свои классифицированные требования в единую базу — можно говорить о машиночитаемом контенте. Затем начинается настоящий космос: создание машиноинтерпретируемого контента путем изложения требований в виде логических выражений (выделение объекта, субъекта, предиката). У нас такие требования чаще называются машинопонимаемыми. И, наконец, появляется стандарт как сервис, то есть некий инструмент, автоматизирующий производственные процессы в соответствии с требованиями стандартов.
Эта схема всем очень понравилась, особенно она впечатлила поклонников всяких инноваций. Оставался открытым один вопрос: как же сказку сделать былью.
Решено было начать с разработки стандарта на SMART-стандарт, чтобы наши славные нормотворцы смогли сразу разрабатывать документы в машиночитаемом или машинопонимаемом (какая, в конце концов, разница?) виде. Собственно, с новой терминологией вышло много путаницы, поэтому как-то само собой заговорили о стандартах в формате XML, которые должны были решить почти все проблемы.
Оставалась самая малость — добиться того, чтобы в цифровой информационной модели присутствовала вся информация, которую можно проверять на соответствие нормам и стандартам. Сперва панацеей считался формат IFC, который магическим образом должен был отображать даже те связи между объектами, которые не были заложены при проектировании. Затем прагматичные экспертизы (СПб ГАУ «Центр государственной экспертизы» и ГАУ г. Москвы «Московская государственная экспертиза») стали выпускать свои требования к цифровым информационным моделям. В конце концов появился стандарт на информационное моделирование в строительстве. И вроде бы всё делалось правильно… но как-то в разные стороны и в отрыве от реальности.
Последний вопрос — вопрос обеспечения единства описания объектов ЦИМ в соответствии с нормами и стандартами — предполагалось решить созданием и применением Классификатора строительной информации (КСИ) для кодирования объектов. Эти же коды должны были использоваться при написании новых SMART-стандартов. Для надежности исполнения задуманного даже выпустили правительственное постановление, обязывавшее применять при проектировании Классификатор строительной информации. Методикой, правда, сперва не снабдили и примеров использования не показали. Но это всё мелочи по сравнению с величием задумки.
Мы рождены, чтоб сказку сделать былью
Долгое время компания «Нанософт» держалась в стороне от вопроса цифровизации стандартов и их применения при проверке информационных моделей, сконцентрировавшись на решении более прикладных задач автоматизации проектирования. Но однажды наступил момент, когда разговоры об инновационных технологиях, сулящих скорейшее наступление светлого будущего, перешли критическую черту, а мы уже не могли сдерживать любопытство. Пришлось приниматься за дело, открыв целое направление, имя которому NSR Specification.
И прямо с порога мы окунулись в суровую реальность:
- технология информационного моделирования, как уже говорилось, во многих компаниях была внедрена только на бумаге, а на практике не существовало даже четкого представления, какой должна быть ЦИМ по уровню детализации, структуре и информационному наполнению;
- у проектировщиков отсутствовал практический опыт применения Классификатора строительной информации;
- отсутствовали и сами SMART-стандарты. К тому моменту уже существовал предварительный стандарт на SMART-стандарт, который разъяснял терминологию вопроса и проливал свет на способы применения. Но все это без конкретных примеров, а желание посмотреть или пощупать было очень велико.
Фактически никто не знал, что проверять в ЦИМ, как проверять и какой должна быть ЦИМ. Слишком много неизвестных для одного уравнения, но отступать было поздно.
Задавай умные вопросы — получай умные ответы
Мы начали с того, что наметили для себя ряд основных вопросов, решение которых должно было способствовать достижению конкретной цели — автоматическому поиску нормативных нарушений в ЦИМ. Итак:
- Как обработать массив действующих нормативных документов для выделения требований?
- Как перевести выделенные нормативные требования в вид логических формализмов, выделяя основные смысловые единицы?
- В каком виде необходимо представлять правила нормативных проверок?
- Как применять Классификатор строительной информации для кодирования объектов ЦИМ и текста требований?
- Каким требованиям должна соответствовать информационная модель, чтобы стало возможным осуществлять автоматические нормативные проверки?
После чего решили разбираться с проблемами по мере их поступления.
Модуль семантической разметки требований
Вопрос обработки нормативных текстов можно было решить двумя способами:
- выделять требования вручную;
- попытаться автоматизировать сегментацию требований.
Мы как IT-компания предсказуемо взялись за автоматизацию. Нам нужен был инструмент, способный прочитать текст стандарта, подсказать границы требований и коды классификации для создания машиночитаемого контента. На полную автоматизацию рассчитывать не приходилось, особенно если учесть опечатки, противоречия и неточность терминологии, которой часто грешат нормативы. Но даже для того чтобы получить автоматические подсказки по обработке текста стандарта, нужно было научить компьютерную программу понимать этот текст. А значит не обойтись без алгоритмов машинного обучения, для создания которых были разработаны онтологические модели предметной области, основанной на Классификаторе строительной информации (рис. 2), нормативного документа и нормативного требования.

В итоге мы получили инструмент, автоматизирующий обработку нормативного текста, который используется командой экспертов при создании базы машиночитаемых требований для подсистемы требований NSR Specification.
Данный продукт является веб-ресурсом, доступ пользователей осуществляется в режиме онлайн. Главная задача подсистемы требований — упростить поиск и анализ информации из нормативных источников и предоставить справку о кодах КСИ, подходящих к тексту требования.
При создании базы нормативных требований в первую очередь обрабатываются документы, обеспечивающие соблюдение положений основных технических регламентов: «О безопасности зданий и сооружений» и «О требованиях пожарной безопасности». Процесс создания машиночитаемого контента является непрерывным и, естественно, учитывает изменения, вносимые в нормативные документы и Классификатор строительной информации.
Более подробная информация о продукте и способах получения тестового доступа найдется на странице www.nanocad.ru/products/nsr_specification.
Модуль семантической обработки NSR Specification, кончено же, не является волшебной палочкой. До сих пор нерешенными остаются вопросы обработки табличных данных и изображений. Но с учетом уже освоенных технологий хочется надеяться, что у нас есть все шансы на успех.
Чем дальше в лес…
Как вы уже поняли, для автоматизации проверки ЦИМ одного машиночитаемого контента будет маловато, нужны машиноинтерпретируемые (машинопонимаемые) требования. Стремиться к которым мы решили путем семантического анализа. В идеале хотелось решить сразу две задачи: получить образцы для апробации проверки ЦИМ и наработать базу примеров для создания алгоритмов машинного обучения.
В ходе работ использовались два варианта семантической разметки.
В первом случае предварительно выделенные требования, полученные из базы данных, передавались в модуль обработки текста, реализующий его аннотацию. Аннотация текста заключалась в генерации дополнительных данных о тексте требования, необходимых для автоматической идентификации токенов, соответствующих размеченным классам, а также для последующей аннотации элементарных требований и семантических элементов в тексте. Использованный алгоритм аннотации текста требований состоял из трех этапов:
- токенизация;
- частеречная разметка;
- синтаксический парсинг.
Результаты использовались при формировании шаблонов, предназначенных для автоматизации данного процесса разметки.
Для второго варианта был выбран формат разметки семантических ролей элементов требований на основе языка OWL. Использовался парсинг разметки семантических ролей элементов требований и ее конвертация в доработанный частично машиноинтерпретируемый формат: на вход подавался TSV-файл, на выходе получался файл в OWL-формате, содержащий машиноинтерпретируемое требование.
Ну, а если попытаться перевести с формально-программистского на общедоступный русский, то семантический анализ до боли в сердце напоминает выделение частей речи в предложении, из школьной практики. Дополняемый указанием связей слов и сопоставлением смысловых единиц требования с кодами КСИ (рис. 3).

И что же со всем этим делать, спросите вы. Именно в этот момент на сцену выходит потребность в программном продукте, где физически будут осуществляться проверки.
Почему CADLib Модель и Архив?
В качестве плацдарма для наших экспериментов был выбран программный комплекс CADLib Модель и Архив, разработка компании «СиСофт Девелопмент». Причин тому несколько:
- особый подход к работе с ЦИМ как с базой данных;
- наличие инструмента для проверки на коллизии с возможностью самостоятельной настойки по собственному сценарию;
- возможность сочетать геометрические и семантические проверки ЦИМ;
- возможность писать собственные приложения.
Помимо этого, поддерживается импорт цифровых информационных моделей из различных форматов, включая всеми любимый IFC, и прямая публикация из нативных форматов BIM-решений на Платформе nanoCAD.
Обрадованные таким удачным решением, мы принялись за разработку конвертера текста требования, подвергнутого семантическому анализу, в XML-формат профиля проверки на коллизии, который можно импортировать в CADLib Модель и Архив.
Вдруг откуда ни возьмись…
Дело оставалось за малым — найти ЦИМ, закодированную по КСИ, чтобы проверить работоспособность создаваемых проверок. Но, как уже сказано, с применением Классификатора строительной информации при проектировании все оказалось не так просто…
- Коды для многих компонентов, функциональных и технических систем, характеристик отсутствовали. Конечно, всегда можно было подать заявку на добавление кода, но ложка дорога к обеду. К тому же исполнение заявок не всегда соответствовало ожиданиям.
- Обратная проблема: наличие различных кодов для одного и того же объекта, системы, характеристики. Например, характеристика «Отапливаемое помещение с логическим типом данных „Да/Нет“» и характеристика «Неотапливаемое помещение» с таким же значением. Или зона «Первый этаж», «Второй этаж» и «Третий этаж» и характеристика «Номер этажа».
- Большинство кодов КСИ содержит ссылку на нормативный документ, но порой в источнике не удается найти соответствующую информацию.
- Отсутствие образца ЦИМ, закодированной по КСИ, привело к тому, что каждый понимал методику применения классификатора по-своему.
В силу описанных трудностей все опытные ЦИМ, созданные различными проектными компаниями, были не похожи друг на друга и ко всем бедам очень отличались от нашего представления об идеале.
Дорогу осилит идущий
Отступать мы и не думали. Поэтому было принято решение поработать над проверкой ЦИМ без учета кодов КСИ. Мы взяли модели, предоставленные нашими заказчиками, и модели, созданные в рамках внутренних пилотных проектов. И, наконец, смогли систематизировать список проблем:
-
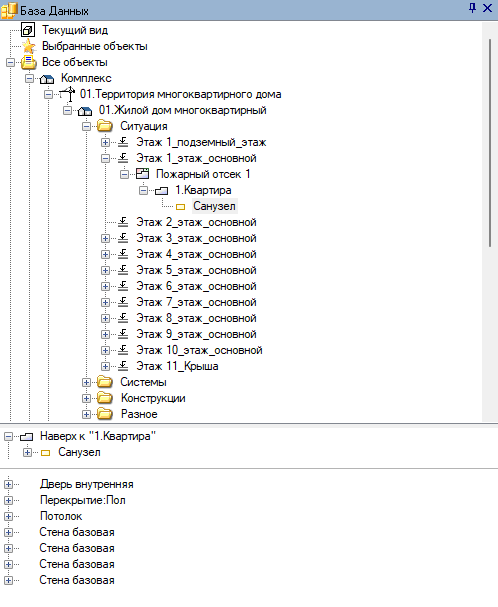
Недостаточная структурированность данных. В идеале нам хотелось увидеть стройную структуру, скелет из площадки, здания, этажей, групп помещений, помещений, зон помещений, на который были бы нанизаны все объекты. Но на практике максимум, который мы нашли в моделях формата IFC, — иерархия с уровнями «Здание» / «Этаж» / «Помещение», причем к зонам помещений было привязано исключительно оборудование. Наверное, на свете есть варианты лучше, но обнаружить такие нам не посчастливилось. Хотя физическая возможность связать строительные конструкции с помещениями существует.
В CADLib Модель и Архив также есть поддержка нужной нам структуры (рис. 4), но на практике проектировщики чаще всего ограничиваются связью объекта с этажом.
- Недостаточность информации о взаимосвязи объектов в сборках. Ступеньки не всегда знают, что являются частью лестничного марша, поручень лестницы вообще чувствует свою независимость, арматурная сетка ведет себя так, будто никому ничего не должна…
- Отсутствие в ЦИМ информации, которая является обязательным условием нормативной проверки. Например, тип лестницы, тип противопожарной преграды или вовсе класс функциональной пожарной опасности здания. Самое удивительное, что перечисленные параметры являются обязательными для классификации в соответствии с техническим регламентом о требованиях пожарной безопасности. Но предписания указывать эти данные в ЦИМ не существует…
- Отсутствие единообразия в описании объектов ЦИМ. Отличается как набор параметров, так и формат заполнения значений. Причем речь идет исключительно о параметрах, которые содержат информацию об имени объекта и его роли в ЦИМ.
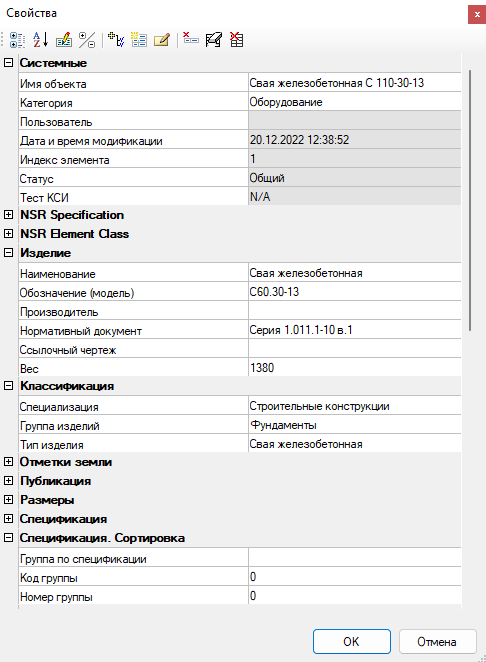
Вот пример хорошего описания — см. рис. 5. Тут указано наименование (Свая железобетонная) и даже есть раздел классификации с указанием принадлежности к глобальной группе Строительных конструкций, и конкретизация, свидетельствующая, что объект является частью Фундамента.
А вот другой пример из той же ЦИМ (рис. 6). Здесь уже довольно сложно разобраться, с каким объектом мы имеем дело, потому что вместо наименования указан размер, а параметры классификации приписывают объект к таинственной группе Составных профилей. Забегая вперед, скажу, что объект является колонной каркаса здания.

Иногда попадаются объекты, об имени которых можно догадаться только по типу IFC, который, как известно, может быть довольно общим.
Откуда такая пестрота описаний?
Во-первых, дело в разнообразии инженерного ПО, используемого для информационного моделирования.
Во-вторых, базы элементов в САПР чаще всего создавались не одномоментно, а в течение длительного времени и разными разработчиками. Основной упор при создании объектов делался на их трехмерном представлении и параметрических свойствах, а не на единообразном описании.
В-третьих, человеческий фактор, по причине которого при проектировании могут быть допущены ошибки в заполнении значений параметров объекта.
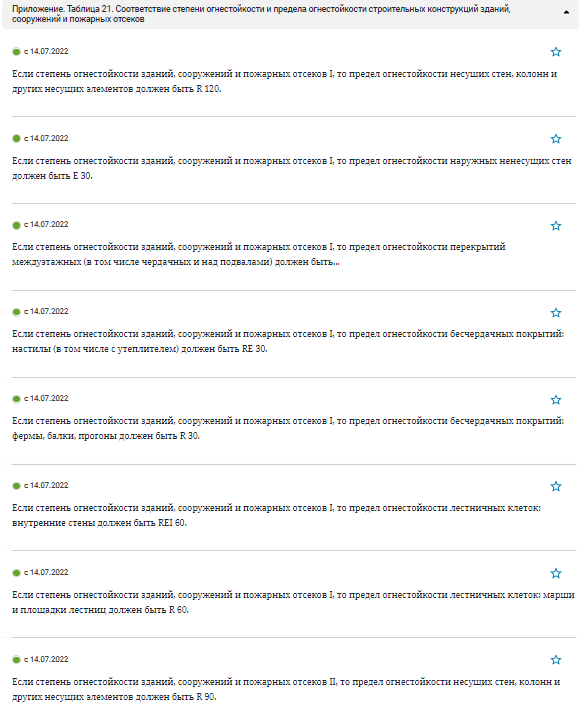
А теперь давайте посмотрим, как нормативные документы описывают объекты требований — на примере Таблицы 21 из Технического регламента о требованиях пожарной безопасности (123-ФЗ) — (рис. 7).
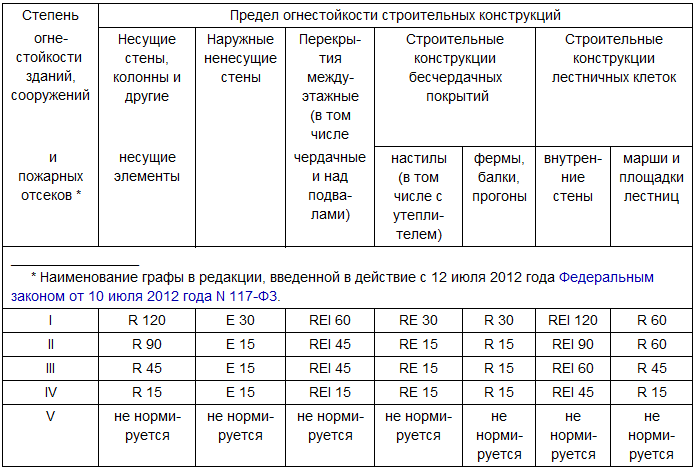
Получается, если мы хотим, чтобы проверка ЦИМ действительно соответствовала тексту нормативного требования, то у конструктивных элементов должны быть указаны следующие параметры:
- общая специализация — Строительные конструкции;
- конструктивная функция (несущий/ненесущий элемент);
- расположение (внутри/снаружи);
- наименование объекта;
- принадлежность к технической системе здания (например, Перекрытия, Стеновая система, Крыша, Фундамент
и т.п.); - принадлежность к технической системе особого типа (например, Бесчердачное покрытие);
- принадлежность к особым зонам здания (например, Лестничная клетка).
Проба пера
После всех сделанных открытий оставалось только сложить кубики пазла:
-
добавить объектам тестовой ЦИМ параметры в соответствии с текстом таблицы (рис. 8);
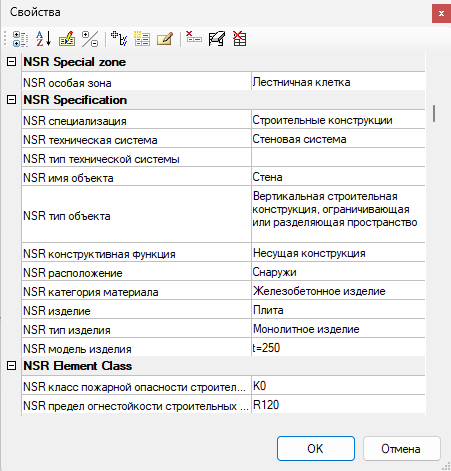
-
создать хотя бы один профиль проверки ЦИМ, соответствующий тексту требования из таблицы (рис. 9);
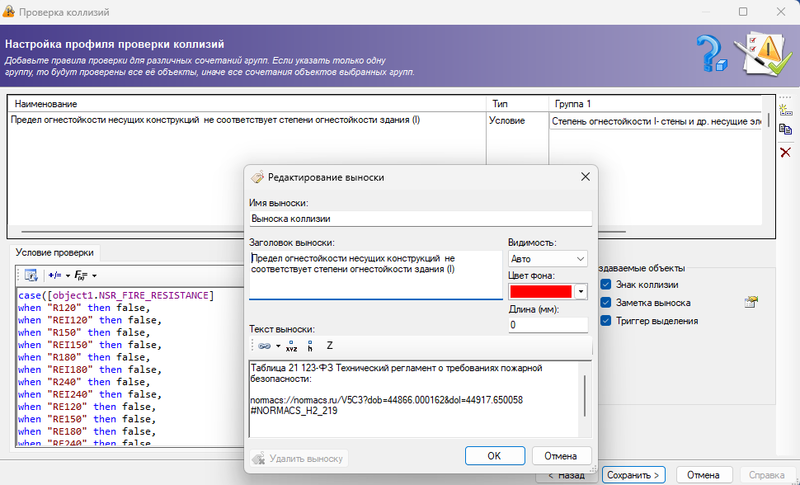
-
обработать таблицу, выделив из нее формальные требования (рис. 10);
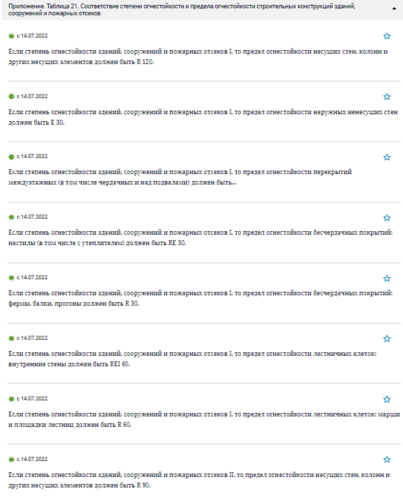
-
произвести семантический анализ каждого выделенного требования (рис. 11);
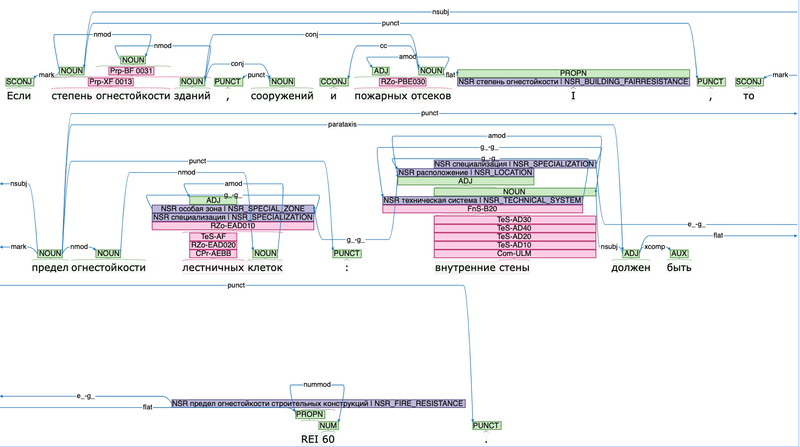
-
произвести конвертацию требований, подвергнутых семантическому анализу, в формат импорта профилей проверки по разработанному вручную образцу (рис. 12);
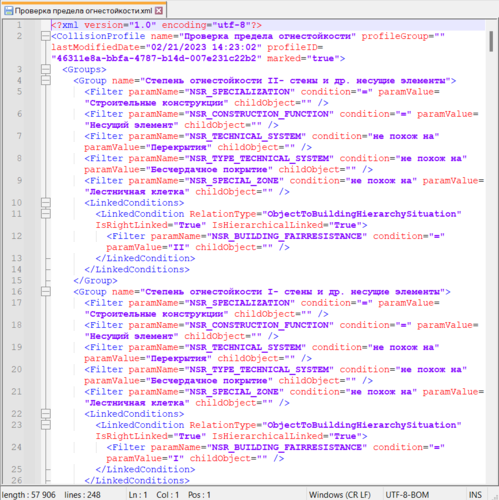
- импортировать полученные профили проверки в CADLib Модель и Архив и запустить их для ЦИМ.


Начнем с хороших новостей: всё заработало (рис. 13).

Используя инструмент проверки на коллизии в CADLib Модель и Архив, действительно можно воссоздать поиск нормативных нарушений и очень наглядно оценить результаты.
Мы не поленились и создали к каждой проверке выноски с текстом нарушения и ссылкой на нормативное требование. Получилось здорово и вдохновляюще!
А теперь к сложностям.
- Если смотреть правде в глаза, то, согласно тексту отобранного требования, необходимо оценивать предел огнестойкости строительных конструкций в зависимости от степени огнестойкости зданий, сооружений и зон пожарных отсеков. Мы же располагали ЦИМ зданий, в которых не были выделены пожарные отсеки. И для первого эксперимента решили просто не брать их в расчет. В принципе, нет особой трудности сделать проверки и для конструкций по пожарным отсекам, но нужна соответствующая ЦИМ.
- Как уже сказано, пока не существует универсального метода извлечения формальных требований из таблиц, которые по своей структуре и логике сильно различаются в российских НД. Поэтому обрабатывать таблицу пришлось вручную.
- В выбранной таблице одни требования фактически являются исключениями для других. Так, первая группа объектов должна включать «несущие строительные конструкции», а это довольно широкое понятие, в которое входят и перекрытия, и стены, и колонны с балками. Далее свои особые требования предъявляются уже к перекрытиям. И выходит, что параметры отбора первой группы объектов должны включать в себя «кроме перекрытий». Профиль проверки на коллизии CADLib Модель и Архив умеет работать с конструкцией «Кроме», это хорошо. А вот автоматическое распознавание исключений при конвертации текста требования в профиль проверки — это может стать проблемой. На данный момент соответствующие изменения вносились вручную.
Тем не менее, эксперимент мы посчитали удачным, решение было одобрено к тиражированию.
Требования к описанию объектов ЦИМ
Так как же соотнести объекты ЦИМ с текстом нормативных требований — с учетом всего многообразия художественных оборотов и вольной терминологии, используемой нормотворцами? На самом деле Классификатор строительной информации и сейчас остается главной надеждой борцов за автоматизацию экспертизы ЦИМ. Но в силу причин, озвученных выше, возможности применять его на практике прямо сейчас — нет.
Поэтому мы решили выработать свой порядок описания объектов ЦИМ, сделав основной упор на группировке объектов (рис. 14). Иными словами, если нормативный документ требует особых характеристик у объектов, являющихся частью каркаса здания, то каждая балка должна знать, что является частью каркаса. В силу того что необходимо было предусмотреть все возможные варианты группировки, от глобальной до частной, выработана иерархия структуры по принципу «матрешки»:
Техническая система → Функциональная группа → Функциональная подгруппа → Сборка → Объект → Деталь объекта.
Пример:
Конструктивная система → Каркас → Бесчердачное покрытие → Ферма → Балка → Крепеж.
Это первая группа характеристик.
Далее мы предусмотрели наличие параметров, которые могут содержать сведения о типе системы, группы, подгруппы, в которую входит объект. Например, Группа «Фундамент» с типом «Свайный». Это вторая часть.
Третья группа характеристик содержит информацию о вхождении объекта в особые зоны, выделяемые в нормативных документах. Это лестничные клетки, пути эвакуации, тамбур-шлюзы. Когда проектировщики освоят создание зон и помещений в структуре здания и привязку к ним, от объектов этой группы характеристик можно будет отказаться. Но пока — так.
И, наконец, четвертая группа — это собственные характеристики объекта. Им мы уделяли меньше всего внимания, потому что большая часть этих сведений уже содержится в описании объектов.

И, самое главное, в центре — собственное имя объекта, которое принципиально необходимо отличать от имени изделия, из которого объект выполнен. В большинстве ЦИМ на этом моменте возникает путаница и колонна начинает называться трубой квадратной.
Кроме этого, был разработан набор параметров для описания зданий и помещений.
Используя разработанную схему описания объектов, команда NSR стала успешно наводить порядок в пользовательских ЦИМ и создавать профили проверок, претендующие на универсальность.
Процесс применения новых параметров получился, конечно, весьма трудоемким. Поэтому параллельно мы стали разрабатывать приложение для CADLib Модель и Архив, автоматизирующее описание объектов по шаблонам. Но, если смотреть правде в глаза, то правильнее закладывать необходимые данные сразу при проектировании. Решить эту задачу мы надеемся через обновление баз стандартных объектов в BIM-приложениях, закрепив эффект BIM-стандартом.
Но и Классификатор строительной информации мы бросать не предполагаем. Подвергая требования семантическому анализу, продолжаем создавать слой разметки с кодами КСИ и разрабатываем схему синхронизации с разработанными параметрами NSR. И у нас даже получилось реализовать успешный пилотный проект с проверкой ЦИМ по кодам КСИ. Но это отдельная история, достойная рассказа в следующей серии J.
Вместо послесловия
Только увидев свет в конце тоннеля в виде практически применимых решений для проверки ЦИМ, мы смогли в полной мере осознать, какого объема задачу взяли в работу, и что шансы на успех были не слишком велики.
Сейчас у нас большие планы на будущее:
- разработка профилей проверок ЦИМ в рамках пилотных проектов для заказчиков, которая позволит создавать осязаемый результат, набираться опыта и копить базу примеров для будущей автоматизации;
- доработка требований к описанию объектов ЦИМ и синхронизация нашей схемы данных с КСИ;
- добавление профилей проверок ЦИМ к базе машиночитаемых требований NSR Specification, доступной широкому кругу пользователей.
Но есть и узкое место, вызывающее особенные опасения: отнюдь не все требования нормативных документов поддаются легкой и безболезненной конвертации в правила проверки не только автоматически, но и вручную.
- Встречаются условия, которые в принципе невозможно измерить с помощью программных средств.
- Встречаются условия, которые сложно измерить по причине функциональных ограничений программы, в которой осуществляются проверки, — например, отбор смежных помещений.
- Встречаются условия, использование которых требует применения нестандартных решений. Например, поиск значения верхней отметки пола последнего этажа.
- Сами требования могут быть неоднозначными в интерпретации.
- Требования бывают сложносочиненными, и одна часть является исключением для другой.
Хорошо работать с требованиями, которые говорят четко: «Ширина путей движения (в коридорах, галереях
Но чаще всего нормативные документы на этом не останавливаются, продолжая: «…допускается ширина коридора 1,5−1,2 м с организацией разъездов (карманов) для кресел-колясок длиной не менее 2 м при общей с коридором ширине не менее 1,8 м в пределах прямой видимости следующего кармана».
Разумеется, такие конструкции надо упрощать, сохраняя смысл и последовательность проверки. И это тоже можно попробовать решить применением семантического анализа и алгоритмов машинного обучения. Так что впереди у нас много захватывающих исследований, о результатах которых мы обязательно будем рассказывать!
- SMART (англ. Standards Machine Applicable, Readable and Transferable) — стандарты, применимые для машин, читаемые машинами и передаваемые на машины. ↑
Скачать статью в формате PDF — 2.64 Мбайт |


