
Главная » CADmaster №4(24) 2004 » Машиностроение Справочно-информационная база данных стандартных элементов, инструмента и материалов
Огромный объем разнообразной информации по стандартным элементам (на основе ГОСТ, ОСТ, СТП), инструментам, материалам
Мы предлагаем подход, основанный на разборе и распознавании наименования, что позволит значительно уменьшить трудоемкость передачи между системами любой информации, содержащей ссылки на стандартизованные изделия.
Типичные примеры, демонстрирующие полезность идентификации стандартных элементов
Интеграция САПР и АСТПП
Предположим, что изделие, разрабатываемое в САПР, содержит стандартные элементы, для которых в САПР имеется библиотека 2D- или 3D-моделей. Далее результаты используются в автоматизированной системе технологической подготовки производства (АСТПП), имеющей свою базу данных по стандартным изделиям (как часть номенклатуры). При передаче информации необходимо, чтобы каждый стандартный элемент отображался на соответствующий элемент номенклатуры. Сейчас, как правило, используется подход, при котором таблицы номенклатуры АСТПП в качестве дополнительных параметров содержат коды элементов в САПР и другую информацию, внутреннюю для конкретной системы. При необходимости использовать в модели стандартный элемент система автоматизированного проектирования должна обратиться к АСТПП, выполнить поиск по своему коду, добавить (если это нужно) элемент в номенклатуру АСТПП, получить и запомнить уже код АСТПП элемента, который будет использован при экспорте спецификации.
Такой подход не свободен по крайней мере от трех недостатков:
- каждая система должна «знать» о другой. Если используется не одна, а несколько САПР, сложность задачи возрастает на порядок;
- для обеспечения работы САПР нередко требуется, чтобы АСТПП работала на том же компьютере, а это уменьшает надежность системы в целом;
- для взаимодействия необходимы либо мощный API с обеих сторон, либо специально проделанные «дырки» в обеих программах.
Взамен существующего метода предлагается следующий механизм взаимодействия. Каждая из систем работает автономно. В модуль экспорта спецификаций и/или ведомостей добавляется код, который нормализует наименование стандартного элемента в импорте и ищет элемент номенклатуры, нормализованное наименование которого соответствует данному. Чтобы ускорить импорт, рекомендуется (хотя это и не обязательно) нормализовать наименования номенклатуры в АСТПП. Для реализации этого подхода потребуется доработать только переходной модуль.
Интеграция ERP-системы и АСТПП
Предположим, что технологические процессы, использующие стандартные элементы, далее экспортируются в систему управления предприятием. Чтобы технологическая информация была привязана к управленческой, она должна содержать ряд управленческих параметров, причем большая их часть приходится именно на стандартные изделия (например, группа изделия, единицы измерения и схемы единиц измерения). Связано это с тем, что планирования закупок требуют именно стандартные изделия. Чтобы решить проблему, ERP-система экспортирует в АСТПП часть своих таблиц, содержащих возможные значения управляющих параметров. Технолог, занятый разработкой технологической подготовки производства (ТПП), должен устанавливать значения управленческих параметров, выбирая их из предлагаемых списков. Непосредственно к ТПП это никакого отношения не имеет, а правильность ввода не контролируется. АСТПП должна иметь возможность импортировать описания параметров — включая список значений, которые они могут принимать.
Предлагаемый механизм позволяет отказаться от предварительного импорта таблиц ERP и трудоемкого заполнения соответствующих параметров в интерактивном режиме: необходимые параметры добавляются непосредственно в момент экспорта данных в ERP-систему. Это вполне осуществимо, поскольку разработанное нами решение способно отождествить наименования элементов в обеих системах. Такой подход позволит и подстраховаться на случай изменения данных в ERP-системе в период между импортом данных в АСТПП и экспортом из АСТПП.
Создание общей базы данных стандартных элементов из нескольких уже существующих
Такая ситуация может возникнуть при слиянии нескольких предприятий. Если задача объединения БД по таблицам и полям, имеющим одинаковый смысл (объединение по вертикали), относительно проста и решается при помощи стандартных средств СУБД, то объединение записей, обозначающих один и тот же объект, как правило, требует ручной обработки всего массива информации. Учитывая, что человек, выполняющий эту операцию, должен обладать определенной технической квалификацией, при большом объеме данных задача становится достаточно трудоемкой.
Предлагаемое решение — автоматический анализ наименований всех стандартных элементов на базе существующих нормативных документов — позволит отсеять ошибочные варианты записей. Во многих случаях при этом выдается диагностика, помогающая определить, в чем именно допущена ошибка. Если эта ошибка не слишком серьезна (использован неверный разделитель, буква другого регистра или символ с похожим написанием — например, «3» вместо «З») и существует возможность автоматически восстановить, что же имелось в виду, возможно автоматическое исправление ошибки. Кроме того, произойдет объединение записей, имеющих разное написание, но одинаковый смысл — таким образом исключается повторное вхождение одного и того же объекта. В дальнейшем исправленное наименование элемента может использоваться в качестве первичного ключа соответствующей таблицы.
Создание БД стандартных элементов предприятия
Ранее база стандартных элементов на предприятиях просто отсутствовала: лучшее, на что можно было рассчитывать, это бухгалтерская информация в «1С» или снабженческие файлы в Excel. Поскольку эти БД создавались с другими целями, они могут быть использованы только как вспомогательная информация для формирования ограничительного перечня. Итак, если необходимо сформировать базу данных номенклатуры при внедрении АСТПП или PDM-продукта, существующий список наименований нормируется, из него исключаются дубликаты и он заносится как объект в БД продукта, где требуется создать базу номенклатуры. При этом возможны дополнительные опции — например, можно исключить типоразмеры, не рекомендованные соответствующим нормативным документом. В принципе списки применяемости типоразмеров могут быть заданы и произвольно — в соответствии с практикой применения на конкретном предприятии. Затем к созданным объектам автоматически добавляются списки параметров, определяющие геометрические, физические, химические и другие свойства объекта. Источником этих свойств служит как нормативный документ, которым непосредственно определяется стандартный элемент, так и связанные документы (например, марка материала изделия определяет его химический состав и механические свойства). Введенные параметры используются внедряемым программным продуктом для технологических, прочностных и других расчетов.
Состав и основные возможности предлагаемого продукта
Предлагаемый нами программный продукт можно разделить на три взаимодействующие части:
- база данных стандартных элементов;
- GUI-клиент («толстый») и web-клиент («тонкий»), предоставляющие пользователю доступ к функциональности БД. SQL-API и С-API для доступа из других программ;
- программное обеспечение для автоматического заполнения БД по текстовым образам нормативных документов.
База данных может поставляться и работать независимо от других компонентов. Второй и третий компоненты требуют БД, но способны работать независимо друг от друга.
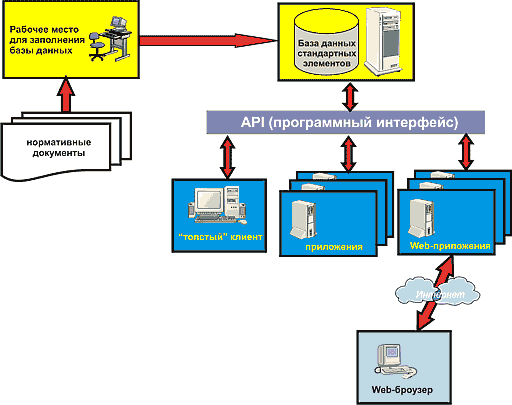
База данных стандартных элементов
Для стандартных элементов существует несколько типов информационных систем. Некоторые из них представляют собой справочные системы, рассчитанные только на пользовательский интерфейс. Основной формат хранения информации для подобных систем — это гипертекст, а их главный недостаток сводится к отсутствию программного интерфейса. Промежуточное положение занимают системы, использующие базы данных только как контейнер, где хранится набор параметров, описывающих стандартные элементы. Формат представления параметров и связей при этом специфичен для каждой системы. Как правило, воспользоваться данными можно только с помощью API, предоставляемого системой: использование данных напрямую затруднено необходимостью формирования очень сложных запросов. К слабым сторонам таких систем следует отнести и то, что данные хранятся в ненормализованной форме — как следствие, возрастет пространство, необходимое для хранения, и замедляется доступ к данным. При разработке нашего продукта мы решили пойти по другому пути:
- максимально использовать функциональность, заложенную в СУБД, вместо дублирования этой функциональности в нашей программе. В частности, вся информация о значащих именах полей, их типах, связях
и т.п. хранится штатным для базы данных способом; - структуру хранения данных максимально приблизить к той, которая содержится в нормативной документации, описывающей стандартный документ. Колонки таблиц базы данных имеют те же имена, что и заголовки таблиц в нормативном документе, при этом исходные таблицы подвергаются ряду трансформаций (объединение, соединение и обратные к ним). Результат представляет собой набор таблиц, которые описывают возможные значения параметров элемента, а также зависимости между ними. Для каждого элемента эти таблицы объединены в схему, имя которой соответствует номеру нормативного документа, определяющего элемент.
Поскольку формат хранения данных достаточно прост, то и извлечь информацию можно при помощи сравнительно простых запросов. В частности, все возможные комбинации типоразмеров и других параметров содержатся (но не хранятся!) в представлении (view), получаемом простым и естественным соединением (natural join) всех таблиц схемы.
Поверх указанной структуры мы предлагаем дополнительную функциональность, которая расширяет сферу применения данных, содержащихся в системе, и по сути превращает «пассивные» данные в «активные» объекты, обладающие интеллектуальными возможностями, обычно присущими лишь человеку. Эта функциональность позволяет:
- «понимать», что означает наименование элемента; извлекать из наименования значения, содержащиеся в нем и зависимых параметрах, а также проверять, являются ли извлеченные значения правильными. При этом спектр возможных вариантов записи наименований достаточно широк. Правильно понимаются символы, имеющие сходное написание (например, буква «А» русского и латинского алфавитов, прописная и строчная буква «Г», буква «З» и цифра «3»
и т.д.). Допускаются сокращенные наименования — например, «Муфта» вместо «Муфта шарнирная». Между полями наименования возможно любое количество пробелов либо их отсутствие. Может использоваться тип разделителя, отличный от нормативного: «.6G» вместо «-6G». Мы привели лишь небольшую часть вариантов, воспринимаемых системой; - вычислять, определяют ли два варианта названия один и тот же объект;
- определять по наименованиям, является ли один элемент частным случаем другого (к примеру, «Болт M4x6.019
ГОСТ 7805–70 » — частный случай «БОЛТ M4Х6ГОСТ 7805–70 », но не «Болт M4−6gx6.019ГОСТ 7805–70 »). Возможность такого анализа важна, поскольку в различных приложениях требуется различная степень детализации одних и тех же объектов; - создавать по выбранным параметрам наименование, полностью соответствующее нормативным документам.
Существенно, что все эти функции внешне реализованы в виде обычных функций языка SQL, а значит и сами они могут использоваться как органичная часть запроса. Так, например, чтобы проверить правильность наименования и, в случае успеха, извлечь значения связанных параметров, достаточно следующего простого выражения:
SELECT *
FROM g7805.parse(`Болт M4x6.019 ГОСТ7805-70`)
NATURAL JOIN g7805.view_mainРазработанные приложения
Прежде всего нам хотелось создать простое приложение, которое, во-первых, предоставляет пользователю большую часть описанной выше функциональности и, во-вторых, без дополнительных трудозатрат стыкуется с любой другой Windows-программой. В качестве механизма взаимодействия был выбран стандартный текстовый буфер обмена, поэтому Парсер наименований CSoft может взаимодействовать с любой программой, поддерживающей команды «Копировать» и «Вставить».

В обычном состоянии парсер наименований неактивен и индицируется в «system tray» наряду с другими системными приложениями, но при копировании текста в буфер обмена он автоматически активируется, развертывая окно свойств объекта, — при этом цвет иконки в «system tray» меняется, показывая статус распознавания.
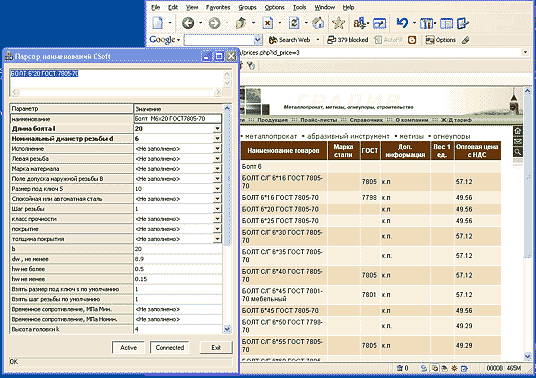
Ключевые параметры элемента можно выбрать из выпадающих списков (доступны только значения, допустимые по нормативным документам). Как результат в верхнем поле окна генерируется правильное наименование, которое через буфер обмена может быть передано в другое приложение. Таким образом, программа может использоваться и для генерации наименований. Кроме того, в парсер наименований встроены некоторые функции поиска.
Достаточно набрать в верхнем поле наименование элемента, чтобы программа выдала список нормативных документов, определяющих элементы с таким названием. Выбор строки этого списка вызывает переход в режим генерации наименования соответствующего элемента.
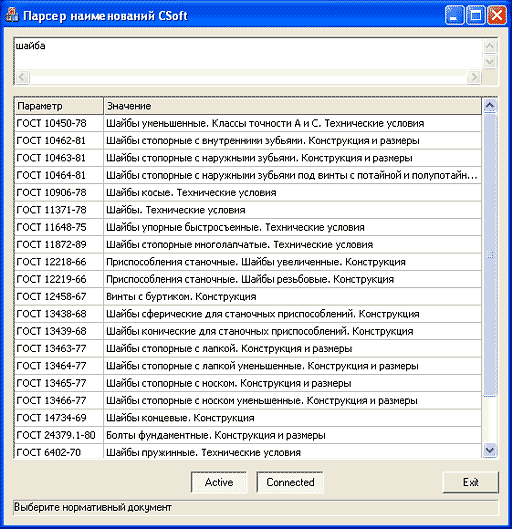
Если известен номер документа (например, номер ГОСТ), достаточно набрать этот номер в верхнем поле программы.
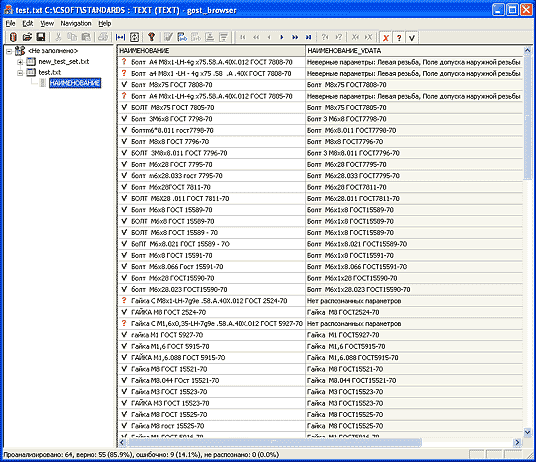
Парсер наименований удобен для интерактивной работы. Что же касается обработки больших объемов данных, то для нее предназначено другое приложение — Анализатор/валидатор стандартных наименований. Идея этого приложения состоит в следующем: получить информацию из произвольного ODBC — источника данных, проверить и, насколько это возможно, автоматически исправить содержимое после чего записать результат в тот же либо другой источник данных.
При работе приложения доступны следующие возможности:
- в случае неправильного наименования происходит анализ ошибки — с выдачей сообщения в отдельной колонке (рис. 5);
- если ошибок нет, генерируется нормализованный вариант наименования;
- пользователь может самостоятельно определять набор колонок, предназначенных для вывода, а также создавать собственные вычисляемые колонки при помощи скриптов на языках Perl, JScript и VBScript;
- скрипты можно подключать и на этапе, предшествующем обработке (это необходимо, если различные части наименования содержатся в разных колонках);
- исправление неправильного наименования возможно в интерактивном режиме;
- на результаты обработки можно наложить фильтр — например, показывать только ошибочные наименования.
Приложение существует в двух вариантах: с графическим пользовательским интерфейсом и в виде сервиса NT, к которому возможно обращение через API. Второй вариант удобен при создании собственных приложений, которые будут в фоновом режиме обрабатывать большие объемы информации. На базе этого сервиса разработано web-приложение, предоставляющее все упомянутые выше возможности, причем пользователю не приходится нести дополнительные расходы на администрирование БД стандартных элементов. Это приложение, которое выполняет разбор наименований и их нормализацию, доступно по адресу http://dev.csoft.spb.ru/ss.
Перечисленные приложения не исчерпывают всех возможных применений базы стандартных элементов. В настоящее время ведутся работы по включению распознавателя наименований в систему полнотекстового поиска (FTS). Это позволит создать индекс для технической библиотеки текстовых электронных документов и практически мгновенно выдавать список документов, содержащих или требуемое наименование, или наименование, логически эквивалентное требуемому. Существующие системы FTS такой возможностью не обладают.
Если пользователь работает в программе, которая позволяет подключать функции из внешней динамической библиотеки (DLL), то база стандартных элементов может быть использована для непосредственного контроля пользовательского ввода.
Технология заполнения базы данных стандартных элементов
Для поддержания базы данных разработана технология, включающая процесс заполнения БД из нормативных документов, существующих в самом разнообразном виде (бумажные, электронные сканированные, электронные текстовые). Этот процесс в значительной степени автоматизирован. Сначала необходимо выверить результаты сканирования и распознавания, затем заполнить конфигурационные файлы (главным образом, определяющие структуру наименования).
Далее автоматически выполняются следующие операции:
- данные проверяются на соответствие типу, отсутствие дублирования и соответствие друг другу наборов значений в разных таблицах. При необходимости могут быть заданы дополнительные критерии проверки — например, возрастание по строкам или столбцам;
- таблицы нормативного документа трансформируются к нормализованной форме так, что их естественное соединение (natural join) обеспечивает полный набор возможных сочетаний параметров стандартного элемента;
- создаются скрипты на языке SQL, выполнение которых приводит к созданию в базе данных структур и объектов, необходимых для работы со стандартным элементом.
Таким образом, все операции, требующие высокой квалификации, — например, проектирование структуры и написание SQL — выполняет программа, а не проектировщик БД. Кроме того, автоматизированная проверка повышает степень достоверности результатов сканирования и распознавания.
Текущее состояние справочно-информационной базы данных
- В настоящее время база данных содержит информацию примерно по тремстам ГОСТам: крепеж, режущий инструмент, в меньшей степени материалы. Указанные данные покрывают более 80% перечня крепежа, типичного для предприятия.
- Поддерживаются СУБД MS SQL и POSTGRES (в дальнейших планах — Oracle).
- Существует открытый web-сервис, обеспечивающий возможность в тестовом режиме провести проверку и нормализацию различных текстовых документов и/или баз данных.
руководитель программных проектов
Семен Козменко,
руководитель отдела программных
проектов
Consistent Software СПб
Тел.: (812) 430−3434
E-mail: valexandrov@csoft.spb.ru,
vkozmenko@csoft.spb.ru
Скачать статью в формате PDF — 325.0 Кбайт |


